Stephen Bustin obtained his Ph.D. from Trinity College, University of Dublin in molecular genetics in 1983. He is currently Professor of Molecular Science at Barts and the London School of Medicine and Dentistry where he aims to apply his research in a more translational setting by doing basic research and clinical practice in colorectal cancer. Bustin’s priority research aim is to translate his lab’s distinctive approach for predicting metastatic behaviour of colorectal cancer into a practical and robust assay for cancer prognosis that is not just more accurate than anatomically-based staging but can identify candidate therapeutic targets in metastatic colorectal cancers.
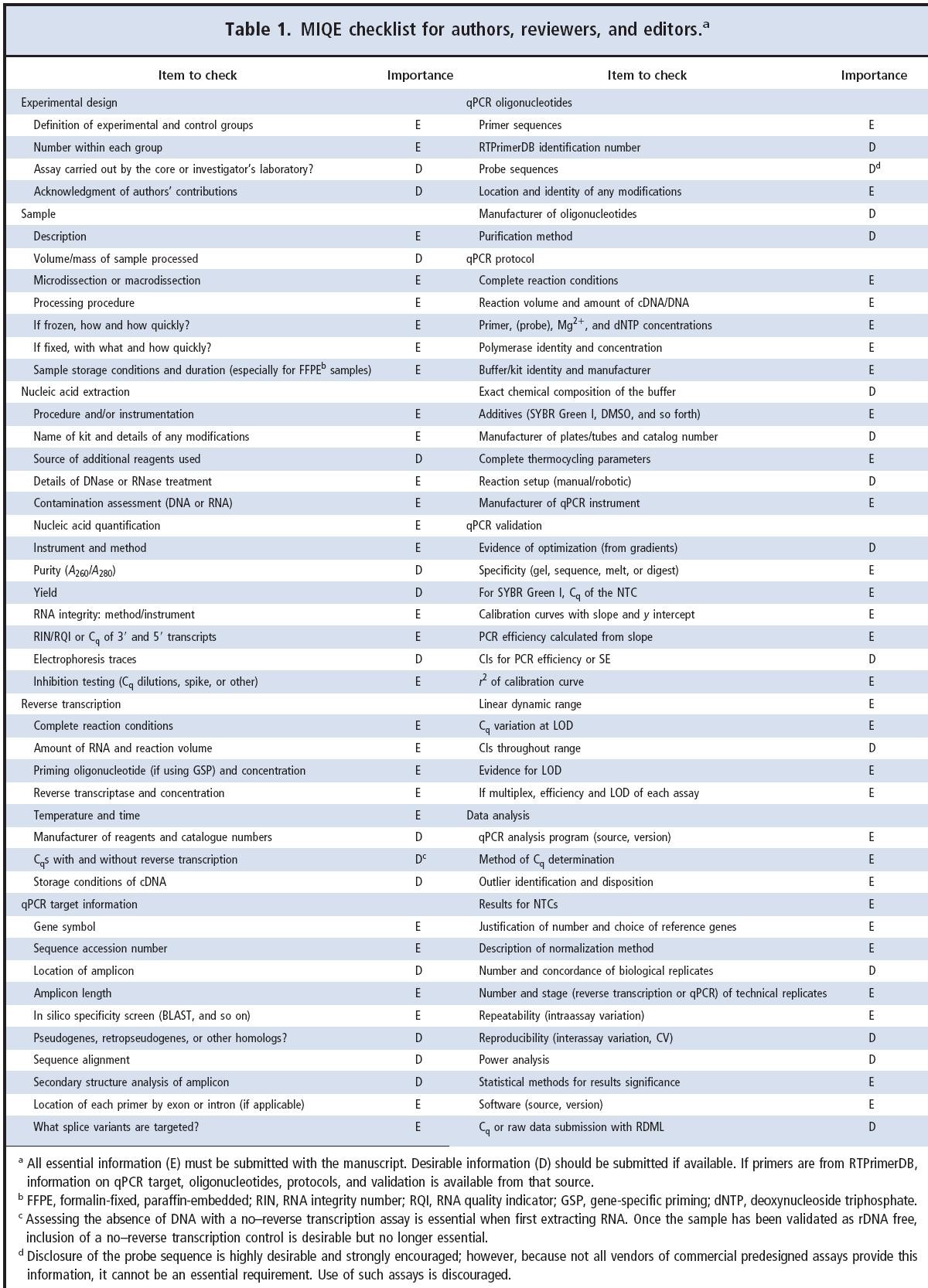
In a seminal paper published in Clinical Chemistry, Stephen Bustin et al. published a new set of guidelines that describe the minimum information necessary for evaluation of quantitative real-time polymerase chain reaction experiments. Following the Minimum Information for publication of Quantitative real-time PCR Experiments (MIQE) guidelines will encourage better experimental practice, allowing more reliable and unequivocal interpretation of quantitative PCR results.
The following is an exclusive interview with Stephen Bustin regarding the story of MIQE and its impact for future publications on qPCR.
Interview
1. Stephen, you are the first author of the MIQE paper that was published at the beginning of 2009 in Clin. Chemistry. The paper describes some essential (59) and some desirable (28) check points for the documentation of quantitative real-time PCR (qPCR) data. What was the idea of the MIQE project when you started it?
When we started back in 1997 using qPCR, it quickly became clear to us that there were a whole range of problems that needed to be addressed. Also, the advice that we were given at the time by the vendors of our real-time PCR instrument didn’t really give us the confidence that our results would be robust and reliable. And even back then it was clear to us that RNA quality would be important because, being a clinical department, we were aware of how the extraction of the sample would be important and that the PCR itself was only a very small component of the whole workflow. It all had to come together to provide a clinically relevant result.
In those days most people were much less aware of these issues. They mostly cared about getting results using this exciting novel technology and whether they were biologically or clinically relevant or not really came second. It was very soon that we realized that there were two problems that needed addressing. There was the whole biological area, which involved being careful about sample selection and data interpretation in the context of, for example know clinical parameters. And there was also the technical side.
Over the years, from other peoples’ publications and some of our own it became clear that the whole PCR process and particularly the reverse transcription-step of course, was characterised by significant problems, and unless each step was controlled very carefully, results would end up being pretty unreliable, variable and certainly would be difficult to reproduce by other researchers. I think that is something obvious to anyone perusing the literature, there are many contradictory and conflicting results, mainly based on the fact that people do not use the same samples, use different protocols and apply different analysis criteria to their data.

2. Did other researchers make similar observations?
Yes, our own worries and concerns were shared and extended over the years by other people publishing problems associated with sample extraction, sample homogeneity, the reverse transcription problem, the whole normalisation conundrum, which I first discussed in 2000 in one of my publications. Jo Vandesompele provided a solution to this, with Michael Pfaffl addressing PCR efficiency questions and Mikael Kubista highlighting the RT-step problems. (1,2,4)
But what really brought the problem to the front of my mind was my involvement with the measles mumps and rubella (MMR) case here in the UK and the US. A paper using RT-qPCR technology published in 2002 purported to show an association between measles virus and bowel pathology in children with developmental disorders. As I was investigating the underlying data in detail it became clear to me that the conclusions supporting that link had nothing to do with the results that the authors had actually obtained. This really moved my attention from unease about what people actually do to concern about what they actually report.

And so through discussions between groups of people with similar concerns, we debated this issue for quite a while and how we could practically end up with a set of guidelines that would make people sit up and pay attention and try to conduct and report their experiments properly. Once we decided we would attempt to design such guidelines, we contacted other influential and well known researchers, such as the qPCR pioneer Carl Wittwer. His involvement had an additional advantage in that he is an editor of the Journal of Clinical Chemistry and immediately suggested that this might be a good vehicle for publicising these guidelines. So we spent several months in discussing, writing, defining, remodelling and refining to come up with an agreed general set of guidelines that was published, not as a “you must do this or else” but as a means to stimulate discussion and raise awareness of the poor state of the scientific literature, at least as it related to qPCR (5,6,7). So these guidelines were published as a blend of all of our involvement, our understanding that there really was a problem and a desire to conceive a document that people could discuss and criticise, but take seriously. It’s always better to have a draft than having nothing concrete to work with.
3. You mentioned the people you’d been working with, the so-called MIQE community. Can you comment on the activity of this community today?
We are a group of academic and commercial researchers that have known each other now for quite a long time and are, all of us, firm friends. I think there are two aspects to participation: When researchers hear about MIQE they are quite interested, and always have some comments on it. We certainly invite anyone who is interested to contact us and contribute, as it definitively is an open community.
It is interesting that companies are extremely supportive of these MIQE guidelines, far more so than journal editors are? That surprised me because if you look at the quality of papers that are produced today in terms of the information that is provided, the situation is no better than it was 10 years ago. If you look at the quality and detail of the information provided by the high impact factor journals, it really is beyond belief, as it is often inappropriate and even misleading especially again in high impact factor journals. The most obvious example I can give you is that of erroneous normalisation. Eight years after the landmark Genorm paper (8), a majority of individual publications still report the use of single reference genes, unvalidated, and very often reference GAPDH or 18S. To my mind people should always want to use the best possible technique, and where possible standards protocols. You know, to me this doesn’t seem to be such a difficult concept.
4. Some people complain that the MIQE guidelines are too restrictive and that it is far away from laboratory reality. Can you comment on these voices?
That is an interesting comment because first of all, all of us that are authors on this paper are active laboratory workers. Having said that, what I do accept is that these are not simple guidelines that you can easily tick off, or that there will be no effort involved in incorporating them into a publication.
They are a stringent set of guidelines and the reason they are a stringent set of guidelines is that qPCR and RT-qPCR are not simple assays. They do involve a very involved workflow, and this starts with how to select a sample and ends with how to analyse and report the data. And so to my mind there is a standard workflow that many people would follow when they design their rt-qPCR assays. You select a tissue, you select a target or a set of targets, you select a RNA extraction method, you select a RNA quality assessment method, you design primers, you make sure they work, you choose a reverse transcriptase, you optimise your assay, you make sure you have an optimal PCR assay, you choose the criteria for accepting Cqs, and you incorporate all appropriate controls. You then decide how you are going to analyse your data, and how you report them. So to my mind, while the MIQE guidelines reflect the complexity of the assay itself, they are a blueprint for a well designed real-time PCR assay. And the paper actually states that a major aim of MIQE is to allow researchers to design better assays.
In practice, if I follow each step from beginning to end to design a de novo assay, then not only should I end up with an assay that makes sense and gives me real data, but I have also fulfilled all the criteria that we suggest should be included with a publication. So yes it is complex, it is somewhat involved, but it’s no more than what you would do if you design an assay anyway, it’s not any additional work. Of course MIQE does not address all the qPCR experiments people do. We hope that people involved in microRNA experiments and multiplexing experiments will contribute their suggestions for the discussion and I am certain that the guidelines will evolve.
One important issue concerns the requirement to publish primer and probe sequences.
We know that small changes in primer and probe sequences, enzymes and experimental conditions can result in different results. Now we discussed this at length and the compromise that primer sequences are essential and probes desirable is what we came up with. We certainly agreed that in order to assess the validity of an assay you really need to know the sequence of the primers. It would be nice to know the sequence of the probe but an assay can be reproduced without that information. So that’s where we are with the potential controversies and concerns.
Pre-designed assays are a sensitive topic, with some vendors providing minimal information with respect to their assays, while others give you the information on probes and primers. So I think it is possible to combine a commercial approach with transparency and I would suggest that if researchers wish to use pre-designed assays, they buy them from companies that comply with this MIQE guideline. People can also use other sources of information like the PrimerDB database. You can get validated assays, they are freely available and you can read other researchers’ experience and assessments (9). So my suggestion would be that people use a transparent commercial assay or PrimerDB if they don’t want to design their own primers and probes.
5. I would like to get back to more controversial points within the MIQE community, what are, in your opinion, the most controversial points?
I think one thing that immediately springs to mind is the whole question about normalisation. How do you normalise? And this is true for both mRNA normalisation and Micro-RNA normalisation. mRNA normalisation has been addressed repeatedly, for example by Jo’s Genorm standard, but also by alternative methods that are readily available for people to use. The problem is most people don’t use them. I think there is a divergence between what people know they should do and what they are actually doing. Methods for miRNA normalisation are being published, although no consensus has been established on how best to normalise. So that is one problem, the other problem is how you actually get a Cq. And I noticed that Bio-Rad is sitting on the fence because you provide both a conventional threshold analysis mode and a “regression” method, which is applied to individual plots and generates a Cq. Clearly, intuitively a method that does not require the setting of a user-defined threshold must be better than one that is subject to individual subjective variation. We have a Bio-Rad CFX instrument and we always check both. And usually there is not an awful lot of difference. However this is an area of active discussion and characterised by numerous publications.
Another problem concerns PCR efficiency: how best to measure efficiency and whether assays should be 100% efficient. I have always taken the approach that I design my assays so that they are as close to 100% efficient as possible using a dilution curve, and so do not need to worry about the use of any correction factors.
Obviously I’m not saying that this is the only approach, and there is considerable debate, as well as numerous solutions resulting in all kinds of interesting approaches to this conundrum.
I think that essentially every single step of the PCR assay is controversial. If I’m looking at mRNA expression, I must know something about the integrity of my RNA and if there are any inhibitors present. Now, that is not controversial. The controversial point is that people don’t actually do that: they don’t look at integrity and they don’t look for inhibition. Yet there is controversy whether these critical data should be reported. And it’s the same with samples: it shouldn’t be controversial that if I’m working with cancer biopsies, I need to be aware that cancers are heterogeneous. So I really shouldn’t take a whole biopsy, prepare RNA and expect to find a robust expression signature, or even a set of clinically relevant biomarkers. I should be far more selective, for example by carrying out laser micro dissection to identify clinically relevant areas of the tumour, such as intravasated cells. But even if tissue is laser micro dissected, as Becky Hands one of my Ph.D. students found, once you start embedding fresh material and then prepare sections from which you isolate RNA, this RNA is very easily degraded and requires continuous quality control monitoring. She ended up assessing her RNA after every handling step. Now, how many people actually look at the RNA quality of each step of this process? We have the data that show very clearly that everything that you do to your tissue affects RNA integrity.
Michael Kubista reported about 4 or 5 years ago, that if you use different reverse transcriptases you get different results. But actually how many people have taken that on board? He has also reported that you have to be careful with your cDNA priming strategies because they can generate different results. These are not controversial topics, the controversy is that people don’t seem to comprehend these facts and factor them into their experiments. And I think you can take it to the very final step, which is reporting. Again it shouldn’t be controversial that if I want to generate a scientific publication I should report what I have been doing.
6. The RDML mark-up language has suggested the use of common terms like e.g.the term Cq (= cycle of quantification) aiming for a common language in qPCR that everyone can follow. We as a company have some internal discussion in terms of the importance of implementation of RDML compliant terms into our qPCR software. What do you think about it, does it have any impact from your point of view?
Yes it has! Because when you decide to buy an instrument, differences in software certainly will be apparent, and some are more user-friendly than others, but after familiarisation all supplied software will generate acceptable data. However, ultimately a decision on which instrument to buy is based on reasoning along the lines of “O.K. I like this instrument, I like this one too but these people were obviously very knowledgeable, they knew what they where talking about, and they can give me the support I need. I’ll go with them”. So the way that people encounter any technology is through the vendor, and this gives the vendor the unique opportunity to make sure people use their instrument and this technology correctly. Why not give an instruction manual that teaches them how they acquire and interpret their data, based on an agreed standard. And I think the way that you sell your instrument bundled with the Biogazelle qBasePlus Software is really far sighted and should be done by every manufacturer.
It encourages you to use a program that implements a certain set of standards, makes the process of obtaining results more transparent and ensures that a result is not based on some subjective or erroneous data handling. In my opinion it is crucial to have manufacturers on board and I’m very gratified to see that there is a universal enthusiastic response. And as I said to you earlier, Bio-Rad’s qbase deal is very good news indeed.
7. Can you comment on how MIQE changed your daily life in the lab, and for your lab staff?
In 1997 we started with the ABI 7700 which we loved, but if you look at it retrospectively, it was terrible because it hid all the problems. It gave you beautiful amplification plots, but never highlighted any associated problems. So we were unaware of things light variable heating of the 96-well block, the need to check fluorescence levels, problems with wandering baselines and so on. I remember coming into the lab every morning and being fascinated with the amplification plots.
Our use of the technology in those days was different of course, in that we expected to take our sample, knowing very little about its integrity and just amplified it and expected a quantitative result. We have always used standard curves and tried to obtain copy numbers based on dilutions of artificial amplicons diluted into tRNA for RT-qPCR or salmon sperm DNA for PCR assays. When we started using qPCR, we were told that quantification extended over a wide dynamic range. However we also quickly realised that if you used widely different amounts of starting material, results became inconsistent. Overall then, it soon became apparent that what suppliers promised wasn’t always what happened in real life. We learnt by our mistakes, using similar amounts of starting material, making sure we were consistent in our priming methods, using a consistent RT protocol and maximised PCR efficiency. So over the years we simply learned to develop protocol that weren’t in every respect MIQE compliant but, together with colleagues’ expertise and experience, evolved into MIQE.
8. Do you think that applying the MIQE guidelines will consistently impact the laboratories’ budget and workload?
We have always tried to design assays and analyse data in a way that reflected best practice at the time. So, obviously, we did lots of things wrong because we did not know any better. I remember a CHI meeting in San Diego in 2001, where I had a slide with four bullet points “Simple, Specific, Speedy and Sensitive”. This is how we perceived qPCR in 2001, and my point was that “It’s none of these”. It certainly is not simple or speedy because you do have to spend a lot of time making sure the assay is right. And it is only sensitive and specific if the assay has been properly designed.
So, yes there is an impact but surely that is better than having to retract papers or end up in a situation where your paper is a significant factor in people’s misery, like the MMR case. qPCR is increasingly finding new applications, making it a massively influential technique. Its inappropriate use is frightening, and the implications are horrendous. Applying MIQE guidelines will save both time and money, as it will result in the elimination of wrong and misleading publications. You may think that I am obsessed with this topic, but it is appalling what’s happening and so to my mind at least the publications of MIQE have encouraged and widened a debate that must include a discussion of integrity and truth, and cannot simply be dismissed as “being too dogmatic”, something I have been accused of.
9. Your concern is that scientists today are generating lots of contradicting results and spend lots of time in the evaluation of these results, in somehow reinventing the wheel?
Look at the whole workflow. Most people would agree now that PCR itself is optimal. After all we can detect a single molecule, if the assay design is right. The problems today are all before and after the PCR step and they need to be addressed. So that’s why I said to you that including qBasePlus is a fantastic step because it really takes care of the whole of the downstream workflow. You can now import the raw data, and the program analyses the quality of the data, it provides an indication of what results mean, does statistical analyses and allows for easy data exchange. That’s perfect. Unfortunately, there are significant and unresolved problems with the upstream workflow. That’s why I think that MIQE is so important because it allows reviewers, editors and readers to ask relevant questions about the assay.
10. This sounds like “You have to get a drivers licence to run your qPCR assay” doesn’t it?
That’s where you come in as a manufacturer: you provide an instruction manual for your instrument. This takes care of the basics. Provision of software such as qBase Plus or MultiD’s GenEx, coupled with training and recommendation of MIQE provides the icing on the cake. A combined effort from researchers, editors, manufacturers and reviewers is required to ensure that certain standards are applied. What they are in detail remains open for discussion, but must revolve around sample preparation, quality control, reverse transcription consistency, PCR efficiency and data analysis guidelines.
11. You are a reviewer for several scientific journals: have you already mentioned a change during 2009 in terms of scientists following the MIQE guidelines in their publications on qPCR?
I don’t think that the response is instantaneous, but we are beginning to see a reaction now. I get a notification when the MIQE paper gets cited and it is beginning to come through now. It is clear that people are beginning to realise that these guidelines exist. This is also due to a series of conferences and meetings that Bio-Rad organised last year in Europe, where people were made aware of the guidelines and obviously communicated with other people.
People are beginning to realise that there is a problem and that can be addressed by following guidelines. Editors’ responses are critical, and I think that’s where our problem lies.
One thing I want to avoid is being seen as a school master. You know, the guidelines do not force anyone to do something in a particular way. What we are saying is: “Look, let’s see whether there is a problem and if we agree that there is a problem, let’s address it”. It might be MIQE, it might be “MIQE light” it might be “MIQE Plus” but at least let’s do something. And there are certain key areas that need to be addressed. I don’t think that anyone would argue that samples need to be carefully selected, that RNA preparation needs careful control and quality assessment, that the reverse transcription step needs consistency, that the assay should be robust and efficient, that appropriate controls must be present and that data must be analysed in a way that is consistent. I think those issues are clear. I think this is what MIQE addresses. So, if you follow the MIQE guidelines you will end up with a good assay. And you will have all the information needed to publish.
12. How did industrial partners and companies like Bio-Rad support your efforts in terms of teaching the community to realise and follow the new guidelines?
It’s interesting to see that companies have been enthusiastic. For me, Bio-Rad was the most involved in that you’ve stepped in and invested a fair bit of money and effort in organising a series of meetings that revolved around MIQE. Others have started to listen as well, as there is a general consensus that the MIQE standard is useful. And I’m very impressed by that, I didn’t expect that.
13. What are the future perspectives and considerations of the MIQE community, what is the outlook?
It would be great if all qPCR users embraced the MIQE guidelines. Certainly it is essential that anyone how wants to use real-time qPCR should be aware of the fact that there are many pitfalls that require the application of certain standards, if results are to be meaningful. And this is so important because qPCR is used across so many disciplines. You got forensic researchers, clinical scientists, basic researchers and so on and there are obviously differences in how a virologist might approach a qPCR assay, as opposed to someone interested in cellular gene expression. But there are certain steps that are in common, so I think we will have a core set of guidelines that everyone will follow, and they include sample selection, quality control, reverse transcription, PCR efficiency and data analysis steps. Eventually there might be several paths leading to qPCR results, but results from different laboratories will be comparable. I’m very optimistic that the whole area of data analysis is being taken care of. We already know that the PCR assay itself is robust and if people use validated and optimised primers and probes - and this could be their own, those available from databases or transparent commercial suppliers - the PCR step will also give no cause for concern.
More details can be found on Stephen Bustin’s MIQE homepage:
http://www.sabustin.org/
References
(1) Pfaffl MW (2001). A new mathematical model for relative quantification in real-time RT-PCR. Nucleic acids research, 29 (9) PMID: 11328886
(2) Stahlberg, A. (2004). Comparison of Reverse Transcriptases in Gene Expression Analysis Clinical Chemistry, 50 (9), 1678-1680 DOI: 10.1373/clinchem.2004.035469
(4)Vandesompele J, De Preter K, Pattyn F, Poppe B, Van Roy N, De Paepe A, & Speleman F (2002). Accurate normalization of real-time quantitative RT-PCR data by geometric averaging of multiple internal control genes. Genome biology, 3 (7) PMID: 12184808
(5) Bustin SA, Benes V, Garson JA, Hellemans J, Huggett J, Kubista M, Mueller R, Nolan T, Pfaffl MW, Shipley GL, Vandesompele J, & Wittwer CT (2009). The MIQE guidelines: minimum information for publication of quantitative real-time PCR experiments. Clinical chemistry, 55 (4), 611-22 PMID: 19246619
(6) Bustin, S. (2010). Why the need for qPCR publication guidelines?—The case for MIQE Methods, 50 (4), 217-226 DOI: 10.1016/j.ymeth.2009.12.006
(7) Lefever S, Hellemans J, Pattyn F, Przybylski DR, Taylor C, Geurts R, Untergasser A, Vandesompele J, & RDML consortium (2009). RDML: structured language and reporting guidelines for real-time quantitative PCR data. Nucleic acids research, 37 (7), 2065-9 PMID: 19223324
(8) Vandesompele J, De Preter K, Pattyn F, Poppe B, Van Roy N, De Paepe A, & Speleman F. (2002) Accurate normalization of real-time quantitative RT-PCR data by geometric averaging of multiple internal control genes. Genome biology, 3(7). PMID: 12184808
(9) Pattyn, F. (2003-1-1) RTPrimerDB: the Real-Time PCR primer and probe database. Nucleic Acids Research, 31(1), 122-123. DOI: 10.1093/nar/gkg011


 Bio-Rad Laboratories is sponsoring a new version of the MIQE qPCR app. Researchers can use the new version to validate their digital PCR (dPCR) experiments according to the recently published digital MIQE (dMIQE) guidelines (Huggett et al. 2013).
Bio-Rad Laboratories is sponsoring a new version of the MIQE qPCR app. Researchers can use the new version to validate their digital PCR (dPCR) experiments according to the recently published digital MIQE (dMIQE) guidelines (Huggett et al. 2013).













{kind=link}